


















At some point in the last eighteen months, someone told you your data wasn't ready for AI. Maybe it was a vendor. Maybe a consultant scoping a six-figure cleanup initiative. Maybe you built something internally after a failed pilot. Wherever it came from, the message was the same: the tool is smart, but your data isn't good enough yet.
This framing has become so pervasive that most revenue leaders have accepted it without questioning it. And it's doing real damage — not because it's malicious, but because it's backwards.
The implication is that your company has failed at a basic hygiene problem. That if you'd just tagged your docs more carefully, curated your knowledge base with more discipline, or invested in content operations, AI would be working for you by now. That the gap between promise and reality is your fault.
It's not.
Your data is messy because you're growing, shipping product, running deals, and serving customers at speed. Conflicting versions of decks exist because messaging evolves. Tribal knowledge lives in Slack because that's where work actually happens. Documentation lags behind product releases because the team building the product is moving faster than the team writing about it.
None of this is a failure of data management. It's the natural byproduct of running a modern revenue organization. Try this exercise: name a single company you've worked at where the internal knowledge was genuinely well-organized. Where every doc was current and every new hire could find what they needed without asking someone. You probably can't. And if you can — ask how much effort it took to maintain, and whether that energy could have been spent closing business instead.
The real problem is that most AI tools were built for a version of your company that doesn't exist — one where every document is tagged, every asset is current, and every piece of knowledge lives in a single, well-structured repository. That company is a fantasy. And tools designed for it will always underperform in the real world.
Scattered Docs, Slack Threads, and Tribal Knowledge: The Real State of GTM Data

If you run a revenue team at a multi-product or technically complex company, you already know what your data landscape actually looks like. It doesn't resemble a well-organized library. It resembles a city that's been built and rebuilt over years — layers of information that partially overlap, partially contradict, and partially depend on the institutional memory of people who may or may not still work there.
Old sales decks sit next to new ones, encoding subtly different positioning. A feature name that changed three months ago still appears in half your case studies. Support tickets are written in engineer shorthand that doesn't map to how sales describes the product. Pricing slides from last quarter are accurate for North America but outdated for EMEA.
And then there's the knowledge that doesn't live in documents at all. The SE who knows exactly how to handle the compliance objection for financial services prospects. The CS lead who can explain the legacy migration path off the top of her head. The PM who remembers why a specific architectural decision was made eighteen months ago. That knowledge exists in Slack threads, in call recordings, in heads — and in hallway conversations that were never written down. And here's the part no one likes to think about: people leave. When that SE who handled every compliance objection moves on, the context for half your financial services playbook walks out the door with them. No two-week transition plan captures what they actually knew.
This isn't a bug. It's the operating reality of every fast-moving GTM organization. The revenue teams that win aren't the ones with the most pristine knowledge bases. They're the ones that can turn fragmented, evolving, distributed knowledge into trustworthy answers faster than their competitors.
Why "Clean your Data First" is the Most Expensive Advice in Enterprise AI

|The standard advice — the one most AI vendors implicitly endorse, and the one a certain class of consultants will happily scope a six-figure engagement around — is to get your house in order before you deploy. Tag your content. Build a taxonomy. Deduplicate. Establish governance. Then, once everything is clean, the AI can do its job.
It sounds reasonable. In practice, it's a trap — and it springs in three ways.
The effort is enormous and is never finished. A data cleanup project requires cross-functional coordination, dedicated resources, and sustained effort over months. It means asking already-stretched teams to pause and categorize content they didn't create and don't fully own. It means making judgment calls about what's "current" in a business where positioning, capabilities, and competitive dynamics shift every quarter. And it means maintaining that structure over time — a commitment almost no revenue org has the bandwidth to sustain.
The cleaning destroys what made the data valuable. When you force messy content into rigid taxonomies to make it machine-readable, you strip away the context and ambiguity that gave it power. A Slack thread between an SE and a PM about a tricky customer edge case doesn't fit neatly into a knowledge base category — but it's exactly the kind of institutional insight that helps someone win a deal six months later. A sales deck that's "outdated" might still contain a positioning angle that kills in financial services. A support ticket written in shorthand might be the only documentation of a product behavior a prospect is asking about on a live call. Clean data isn't necessarily useful data.
The world doesn't pause while you organize. New features ship. Messaging changes. Customers churn and new ones arrive with different requirements. The knowledge base you spent three months curating is already drifting by the time you finish. The cleanup never ends, the value is always deferred, and the teams who need help the most — the ones operating at the highest speed and complexity — are the least able to stop and organize before they can move forward.
Your AI Doesn’t Need Cleaner Data. It Needs to Understand What Your Data Actually Means.
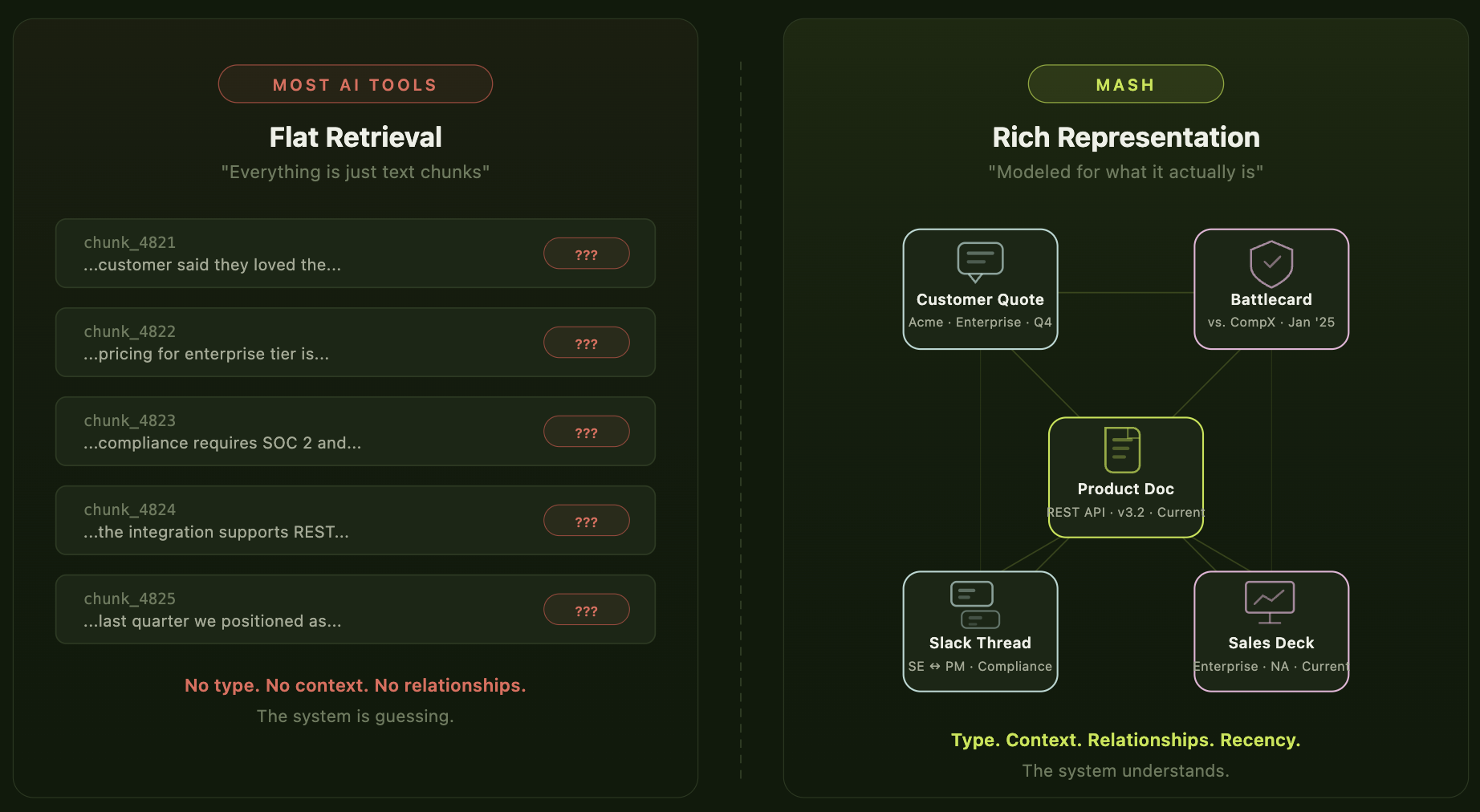
If "clean first, deploy later" is a trap, the alternative isn't lower standards. It's a fundamentally different architecture — one that can ingest content as it exists, build structure around it automatically, and reason about it in the context of how your business actually operates.
Most AI tools treat all content as interchangeable text. A customer quote, a roadmap update, a support ticket, and a competitive battlecard all get reduced to chunks, embedded in a vector store, and retrieved based on similarity. The system doesn't know what those things are. It doesn't know a quote is tied to a specific customer and outcome. It doesn't know a battlecard should only surface if it's been updated since a competitor's last launch. It doesn't know a slide reflects last quarter's positioning and should be deprioritized.
The distinction that matters is between retrieval and representation. A system that merely retrieves text based on similarity is guessing. A system that represents information with type, relationships, and context can evaluate what it finds. In GTM — where a wrong answer costs you a deal, a relationship, or your team's trust in the tool — guessing isn't good enough.
This is the architecture we built Mash around. Connect it to your existing systems — docs, Slack, CRM, call recordings — and it doesn't ask you to clean anything first. Instead, it builds context around each piece of information: a customer quote gets treated differently from a battlecard, which gets treated differently from a Slack thread, because each one means something different when a rep needs an answer on a live call. Conflicting decks aren't a problem; they're a signal the system understands and resolves. Outdated content gets deprioritized based on recency. Tribal knowledge doesn't require formal documentation to become useful.
Aaron Dolan, Head of Solutions Engineering at Triple Whale, lived this exact pattern. He was spending 15–20 hours a week answering questions from AEs and customers — the majority of which had already been answered somewhere in Slack or docs. That's not a knowledge gap. It's a retrieval gap.
It was scattered, messy, and hard to access — but it existed. What was missing was a system that could make sense of it without asking anyone to reorganize first. Aaron Dolan, Head of Solutions Engineering at Triple Whale, described spending 15–20 hours a week answering questions from AEs and customers — the majority of which had already been answered somewhere in Slack or docs. That's not a knowledge gap. It's a retrieval gap. The answers were there. The system just couldn't surface them.
The Compounding Gap: Why Teams That Move Now Pull Away From Teams That Wait
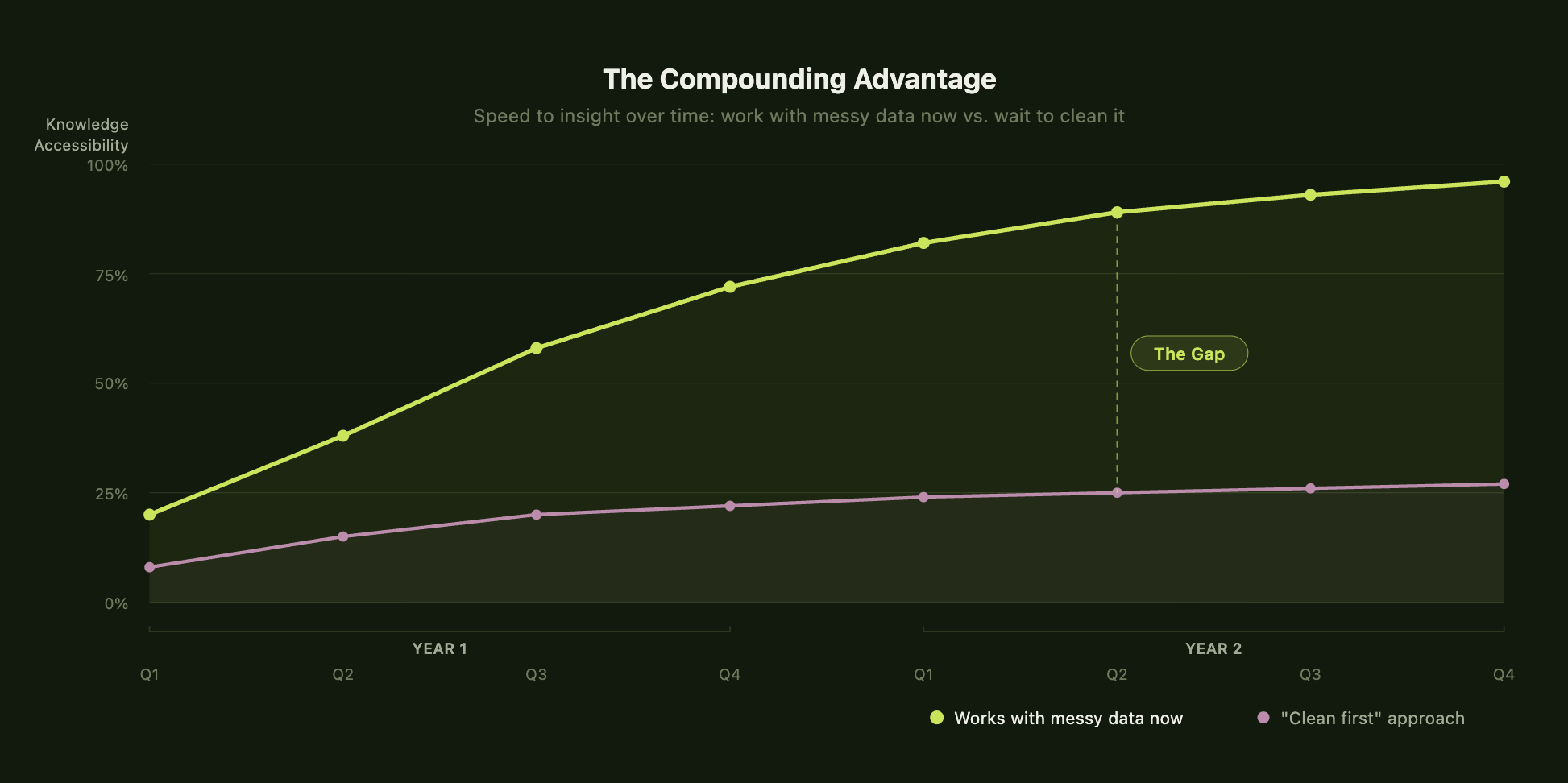
Here's the question worth sitting with at the leadership level: what is the actual competitive advantage in GTM right now?
It's not who has the cleanest data. It's not who has the most comprehensive knowledge base. It's who can turn distributed, evolving, messy internal knowledge into trustworthy answers fastest.
How fast can a rep get from question to confident answer on a live call? How quickly can a new SE ramp without leaning on the same three senior people for every edge case? How reliably can a CS manager pull the right proof point for an expansion conversation without a 30-minute scavenger hunt?
Every one of those moments is a leverage point. And they compound. A rep who trusts the system uses it in front of a customer. An SE who finds the answer without interrupting a colleague saves everyone's time. A revenue leader who gets insight instead of raw data makes better bets on where to focus. Multiply that across every call, every deal, every quarter — and the gap between teams that figured this out and teams still running cleanup sprints gets very wide, very fast.
The most successful GTM organizations we work with have stopped trying to fix their data and started building systems that can think inside it. They've accepted that the chaos is permanent and invested in tools designed for that reality.
Your data is messy. It always will be. The question was never how to fix it — it's whether your tools are smart enough to stop asking you to.