

















AI for go-to-market (GTM) teams is everywhere, and what many of them promise is certainly alluring: connect all your tools, sync your business data, and you’re supposedly "AI enabled". Sales decks, product docs, case studies, call recordings; suddenly unified and searchable, with an AI system now able to sift through it all and understand the nuances of your business.
But there’s a quiet gap between what these systems appear to do and what they actually do. Most AI tools don’t truly understand your GTM data.
Under the hood, many of these platforms are serving what we think of as data soup: a swirling mix of unstructured fragments containing all your GTM data that looks relevant but lacks real meaning. Accuracy matters for fast-moving revenue teams operating in highly regulated or technical environments, where delivering incorrect information about your product feature or its technical capabilities to a prospect can cost a deal.
Below, we explore why naive retrieval-based AI breaks down in real GTM environments, why chunking is not the same as understanding your data, and why the next generation of AI systems must shift from simple retrieval to more nuanced data-representation.
How Most AI-for-GTM Systems Actually Work
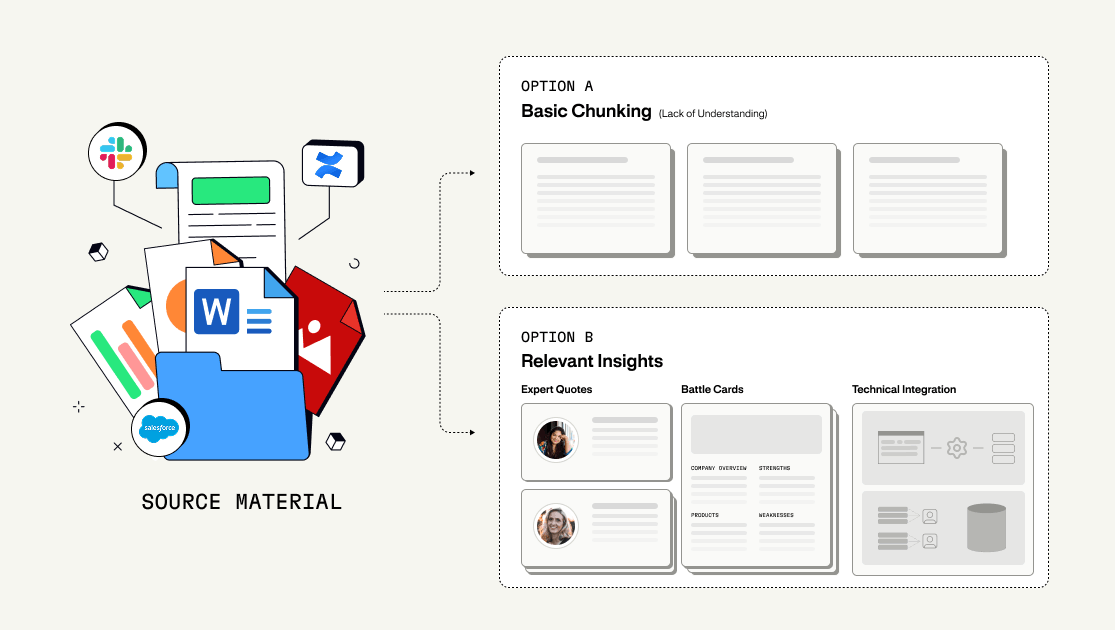
Despite differences in branding and UI, most AI-for-GTM platforms rely on the same underlying architecture. They connect to your existing tools, like Google Drive, Salesforce, Notion, Gong, etc. and then ingest all of this content in more or less the same way. Large files are broken into smaller chunks of text so language models can process them. Those chunks are embedded, indexed, and retrieved when an end-user (like an AE on a live demo call with a prospect) needs to retrieve specific information and answer a question.
At first glance, this feels powerful. Everything becomes searchable. You can ask questions in natural language and receive answers pulled from across your internal knowledge base. It's easy to feel like the system “knows” your business. The problem emerges once real GTM data enters the system.
In practice, GTM content is messy and constantly changing. Old decks live next to new ones, with those decks encoding different versions of product messaging. A quote embedded inside a case study may reference a specific product feature that has since evolved. A feature mentioned in a sales call transcript may differ from what is documented in the current enablement materials. Pricing slides may apply only to a specific region, customer tier, or contract type. Permissions on proof vary by customer, segment, and channel. Case studies age out or become invalid when products change or customers churn.
None of this complexity disappears when its indexed by a basic AI system, and the inability to approach the data with nuance can lead to disastrous situations. When you query a chunk-based RAG system, it will return something semantically relevant, but it has no real understanding of whether that content is right for the situation.
Why Chunking Is Not Understanding
Most RAG-based systems promise intelligence by adding context, but the reality is that they often just accelerate an old problem: garbage in, garbage out.
Context via RAG is commonly treated as the missing piece for making large language models useful for business. The simplest and most widespread way teams attempt this is through naïve chunking: breaking documents into smaller pieces so they can be embedded, indexed, and retrieved within a model’s context window.
This approach simply addresses a mechanical limitation.
Chunking makes it easier for models to access more text, but it does nothing to improve the quality, meaning, or structure of the underlying information. The system still has no understanding of what the data represents, how it should be used, or how it relates to other knowledge across the business. Instead, it creates a false sense of intelligence: because something relevant can be retrieved, it feels correct, even when it isn’t.
Chunking a sales deck strips away the narrative arc. Chunking a customer quote removes the deal context. Chunking a product doc disconnects features from their release timelines and approval status. You’re left with isolated fragments that mention things, but don’t mean things in a way the system can reason about.
This loss of context creates a dangerous illusion of relevance. The AI can tell you that a chunk mentions Feature X, but it can’t tell you whether Feature X is appropriate for this customer, at this stage, in this region. GTM teams often assume the system is making informed choices, when in reality it’s guessing based on surface-level semantic similarity.
Those guesses can be costly. A misleading answer from an AI system doesn’t just waste time, it can derail a conversation, undermine trust, increase churn risk, or jeopardize a deal.
From Retrieval to Representation
To move beyond these limitations, RAG systems need to shift from simple retrieval towards representation.
Representation, in the context of a well-designed knowledge engine, attributes deeper meaning to data sources that go beyond searching for text. It combines content with metadata, relationships, and context so the system understands what something is, not just what words it contains.
Instead of treating everything as flat text blobs, representation-based systems model GTM information in ways that reflect how teams actually use it. A customer quote is represented as a quote, tied to a specific customer, product, feature, and outcome. A slide deck is part of a narrative, connected to an audience, a moment in time, and a messaging goal. A video is more than just a raw text transcript, it’s a source of structured signals like products discussed and objections raised.
This layered structure allows the system to reason about relevance. It can evaluate not just whether something matches a query, but whether it makes sense to use now, for this customer, under these constraints.
Why Chunk-Based Systems Break in Production
Chunk-based systems often look impressive in demos, where the data is clean, the queries are scoped, and the responses feel precise.
In production, reality intrudes. Contradictions tied to conflicting data sources surface. Outdated content competes with new messaging and users are forced to validate, cross-reference, and apply judgment manually. The system retrieves, but the human is left doing the actual reasoning.
This becomes a bottleneck for fast-moving teams that can’t afford to slow down every time a quote needs to be vetted, a case study needs to be matched to a segment, or a product reference might be out of date, especially when the cost of a delayed or inaccurate response can be the difference between progressing or losing a deal. What’s worse, chunk-based systems require you to pre-clean and pre-structure your data, which not only introduces a massive setup tax, but also forces you to discard messy or ambiguous content that doesn’t fit the mold, even if it holds real strategic value.
The result is a system that may appear accurate, but fails to be helpful in practice, because it can’t apply context, evaluate relevance, or reason across sources. And without that layer of structured understanding, modelled around how GTM teams actually operate, even the most advanced AI agents are limited to shallow retrieval, unable to support real workflows in a meaningful way.
Mash’s Approach: Context-Rich Representations
At Mash, we approach GTM data differently. Instead of flattening everything into text chunks, we build layered representations around each piece of information.
Every asset is wrapped in contextual layers that capture how it should be used and understood. These layers include an understanding of product and feature alignment, customer segment, deal stage, recency and approval status, intent and tone.
Each layer adds reasoning power. Together, they allow the system to weigh relevance, resolve conflicts, and adapt as your business evolves. Quotes reinforce or invalidate other quotes. New slides supersede outdated ones. Positioning shifts as products change.
Because the data is self-referencing and structured, meaning becomes actionable.
Designed for GTM Chaos
Most AI systems assume clean, curated inputs. Mash assumes the opposite.
We design for the messiness that operating a revenue team in a high-growth software company invokes, and understand that conflicting decks, overlapping messaging, and scattered knowledge sources is the reality. Instead of breaking under that complexity, our system analyzes, models it, and makes sense of it.
For GTM teams, this shift changes everything. You’re no longer spending hours searching for content, or bogged down by the reality you have no clue which of your internal docs is even relevant anymore – you’re getting supporting information and collateral you can trust.
Trustworthy answers arrive faster, with higher accuracy and less second-guessing, leading to a reality where teams spend less time digging through folders or validating AI output, and more time engaging prospects and closing deals.
The Future of AI in Revenue Workflows with Mash
The next evolution of AI in GTM isn’t more complex DIY agent builders or no-code workflows. You can’t get away with connecting your software and data sources to a broad-built AI system and call it a day. You need a system that truly understands business context and what every bit of your data actually represents so you can enable teams of AI agents to make sense of it downstream.
We’re moving from content fetching to content reasoning and from indexing data to modelling how GTM teams actually think and operate. To unlock the real value of AI in revenue workflows, systems must move beyond simple keyword and semantic retrieval to contextualized insights that represent, reason, and recommend off of your data.
Thats precisely what we’ve built Mash to do.