

















Introduction: Why This Matters to Revenue Leaders
As AI becomes more embedded in go-to-market workflows, there's growing enthusiasm around Model Context Protocol (MCPs). And to be clear, that enthusiasm is valid. MCPs make it easier to expose internal systems through APIs, standardize how tools communicate, and allow AI applications to issue structured queries across an increasingly fragmented tech stack. For infrastructure and platform teams, this creates much-needed flexibility.
But for revenue leaders who are focused on outcomes like team efficiency, messaging consistency, and deal velocity, the role of MCPs is often overstated. They're being framed as intelligent systems that can guide reps in real time, when in fact they are better thought of as infrastructure primitives. They can access data, but they cannot reason with it.
This distinction matters. Because in the high-pressure world of B2B SaaS—where outdated content, shifting positioning, and complex customer contexts are the norm, access without understanding doesn't solve the problem. It introduces new risks, increases rep burden, and often slows deals down.
If you've ever seen a rep send a slide with deprecated messaging or a quote from a churned customer, you've already seen the consequences of mistaking retrieval for intelligence.
What MCPs Actually Do (and Why They're Still Useful, but Limited)
At their core, MCPs are API orchestration layers. They give you a standardized way to query different systems with basic questions & searches—your CRM, help desk, product release notes, knowledge base—without building direct, custom integrations every time. From an infrastructure perspective, this is a big improvement. It makes it easier for AI tools, bots, or internal dashboards to ask consistent questions like:
- "What are the most recent product updates?"
- "Pull the last 10 support tickets for this account."
- "Show open opportunities from Salesforce."
For simple, scoped, quick access like these, MCPs work well. They reduce integration complexity, improve reliability, and enable lighter-weight tooling across the stack. In technical circles, this is why MCPs are often discussed in the same breath as enterprise search or AI-powered workplace tools.
But as a revenue leader, the more relevant question is: Do they help your team sell better, faster, and more consistently while breaking down silos, deeply understanding the product to nail the spiffs, and delivering top-tier, white-glove service to every customer?
And the answer, in most cases, is no—but not for the reason most people assume.
To be fair, MCPs aren't limited to one-shot lookups. Modern LLM-powered systems can chain multiple MCP calls together, attempting multi-hop reasoning on the fly. You'll see this in tools like ChatGPT: the model figures out it needs a calendar search, then a CRM lookup, then a transcript pull, then a doc search—issuing a sequence of basic CRUD-style MCP calls and trying to stitch the results together step by step.
The problem is that this puts the entire burden of domain-specific reasoning on the LLM at inference time. It's improvising a plan of attack with generic building blocks, and it often fails—or produces unreliable results—when the logic required is deeply contextual to how GTM teams actually work. The MCP layer makes content accessible, but it doesn't make it usable in context. That gap between access and application is where most of the risk lives.
Where MCPs Break Down in Real GTM Workflows
Sales and revenue teams don't operate by firing off disconnected questions, because the work they do is inherently contextual—every ask is tied to a deal, a customer moment, or a decision they need to make quickly. So when a rep is chasing an enterprise opportunity, they're not really asking for "last week's support tickets" in isolation; they're trying to understand what's changed, what's risky, and what context will help them move the deal forward.
They're trying to figure out whether a recent bug impacts the feature they're about to demo or whether they should proactively message a customer who relies on it. They might be scanning a meeting-prep doc to spot a product signal that's ripe for an upsell. They're wondering if the quote they want to use is still approved, whether that case study still reflects current messaging, and whether the deck they're using was created before or after the latest pricing change.
And the point isn't to dump a Slack firehose in their lap. It's to surface only the important, curated context—tickets, docs, and tribal knowledge—so they can act with confidence.
This is where MCPs hit a wall. Not because they're limited to single queries, a capable LLM can chain multiple MCP calls and attempt to reason across the result, the real issue is what you're handing the LLM to work with.
Think of it this way: giving a generic LLM a set of basic MCPs is like giving a TaskRabbit handyperson some plywood planks and a hunk of raw steel and asking them to build a bookshelf. They might figure it out, eventually, but the materials aren't shaped for the job, there's no design to follow, and the result is unpredictable. What you actually want is the equivalent of handing a skilled carpenter a hammer, nails, pre-cut wood, and a blueprint. Same goal, radically different execution.
Basic MCPs are the plywood and steel. They give you web_search, notion_search, call_transcript_lookup, generic primitives that the LLM has to learn to sequence, interpret, and reconcile on the fly, for every single query, with no guarantee it gets the domain logic right. The LLM will maintain shared memory across the call chain, and it will attempt to reconcile relationships between the data it pulls back. But it's doing all of that improvisationally, without any of the GTM-specific structure that would make those operations reliable.

And that improvisation is fragile. The model doesn't inherently know that a customer quote came from an account that churned, that a slide was replaced last month, or that a document is out of date and no longer on-message. It doesn't know how to prioritize a verified enablement answer over a messy Notion doc. It can try to figure these things out by issuing more calls - searching the CRM for account status, checking doc metadata, cross-referencing timestamps - but each additional hop introduces latency, error risk, and the very real possibility that the model takes a wrong turn and delivers a confident-sounding answer built on shaky ground.
For CROs, this creates friction at scale. Reps spend time interpreting results instead of selling. Enablement teams are left cleaning up after content misuse. And critical moments, like responding to a product question mid-deal, become slower and riskier.

A Real Example: Multi-Hop Reasoning in the Wild vs. Domain-Aware Intelligence
To see why this matters in practice, consider a scenario with real domain complexity—the kind of multi-step question that GTM teams deal with constantly.
A rep finishes a call and needs to follow up quickly. They ask their AI assistant: "What was the last question the CTO from that shoe company customer asked on our call last week?"
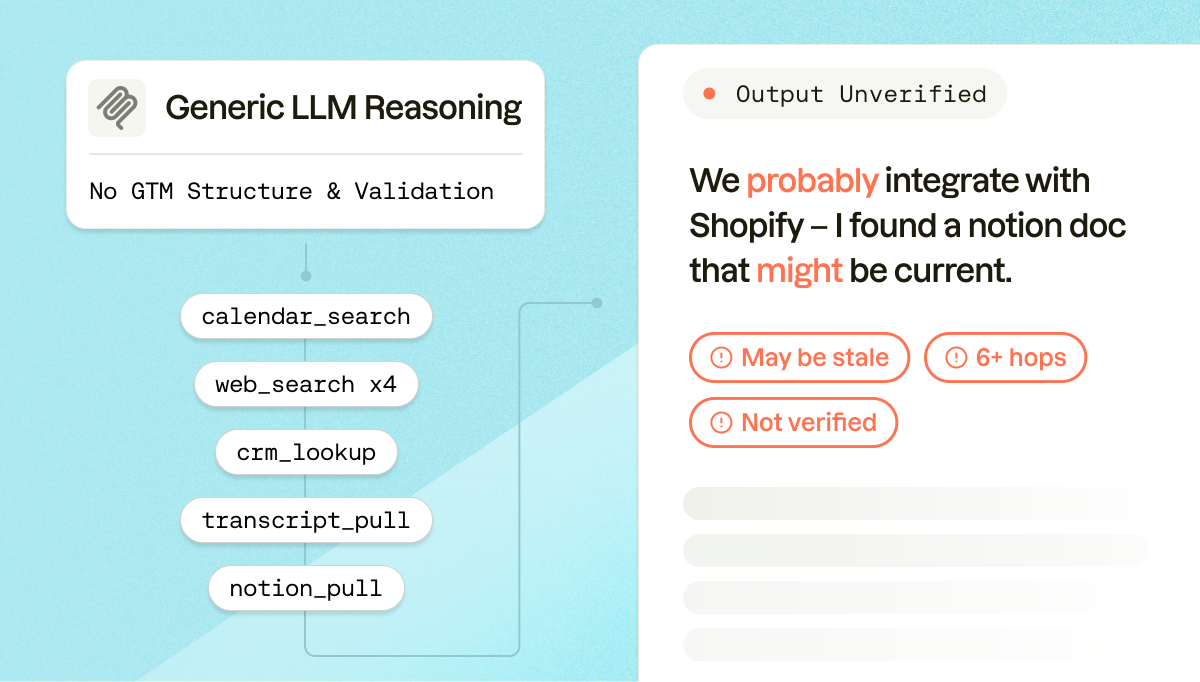
Simple enough as a question. But watch what a generic LLM armed with basic MCPs has to do behind the scenes:
1. Calendar search. The system doesn't know which "shoe company" you mean, so it starts by pulling last week's meetings. → calendar_search("last week") — Five calls come back.
2. Industry identification. Now it needs to figure out which of those five accounts is a shoe company. It has no structured industry data, so it tries web lookups. → web_search("Nike industry"), web_search("Cisco industry"), and so on for each account.
3. Contact lookup. It determines the call was probably with Nike. But who's the CTO? Maybe the CRM knows. → crm_account_search("Nike") — It finds the CTO is John Doe.
4. Transcript retrieval. Now it needs the actual conversation. → find_call_transcript("Last Friday", "Nike", "John Doe") — It pulls the transcript.
5. Transcript analysis. The model reads through the full transcript, tries to identify the last substantive question before the call wrapped up, and lands on: "Do you integrate with Shopify?"
6. Answer lookup. Now it needs to answer that question. It searches internal docs. → notion_search("Shopify integration") — A few messy Notion pages come back, partially outdated, with conflicting information. The model does its best to synthesize a response and presents its best guess.
That's six or more MCP calls, each one a branching point where the model could take a wrong turn, misidentifying the account, pulling the wrong transcript, misreading the question, or surfacing a stale doc as though it were authoritative. And at the end of all that work, the rep gets an answer the system isn't actually confident in, built on a chain of improvised lookups with no validation layer.
Now consider the same question routed through a system with domain-aware data modeling:
1. Structured question log. The system already has a purpose-built tool that indexes customer questions from calls, tagged by account, contact role, industry, and date. → customer_question_log_search("last_week") — It immediately surfaces that the CTO at Nike (tagged: footwear/retail) asked about Shopify integration on Friday's call.
2. Verified answer retrieval. Instead of searching through raw Notion docs, the system queries a curated, validated knowledge layer. → verified_answer_lookup("do we integrate with Shopify?") — It returns an enablement-approved answer with a confidence signal and a timestamp.
Two calls. Clean data. A verified answer. The rep responds in minutes with something they can trust.
The difference isn't that the first system can't try to get there, it absolutely can, and sometimes it will. But every step requires the LLM to improvise domain logic that the second system has already encoded. The generic approach doesn't give the model shortcuts to commonly needed things; it forces it to rediscover the path every time. And in GTM, where the cost of a wrong answer isn't just wasted time but eroded trust, deal risk, and compliance exposure, that improvisation is a liability.
This isn't just a bad lookup. It's a breakdown in trust. And when reps don't trust the system to give them helpful, accurate, and context-aware information, they stop using it altogether. The tool becomes shelfware, and your team reverts to manual workarounds.

Search Is Not Understanding - And That Distinction Matters
This failure mode is not about weak interfaces or missing integrations. It's structural, because most MCP-style connectors are designed to retrieve content, not interpret it, and that gap shows up the moment a team tries to use the results in real customer work.
MCPs make information accessible, but they do not understand it first. Without real comprehension, what you get back is often closer to keyword search than trusted context: fragments that might be relevant, alongside content that is outdated, nonsensical in the current situation, or simply untrue once you account for timing, approvals, or the customer's history.
It's the equivalent of giving your revenue team personalized Google search for all your knowledge sources and asking them to determine the relevancy and accuracy themselves.
Worse, that raw output is frequently passed straight into an LLM, where it gets blended together, paraphrased, and rewritten into something that sounds confident. If the underlying inputs are wrong, stale, or mis-scoped, the model can still produce a polished answer that looks usable, and the rep may not realize it has quietly crossed a compliance line, repeated a revoked claim, or pulled a "great quote" from a churned account.
In practice, the burden stays with your reps. They still have to interpret relevance, check whether collateral is approved, confirm that messaging is current, and decide whether something should be used at all. The experience feels like a smarter search box, except the filtering work is now hidden inside a workflow that encourages speed, which makes it easier for questionable content to slip into customer conversations.
And when you scale that across a large GTM team, the promise that AI will save time often fails to materialize for the most nuanced, time-sensitive jobs-to-be-done. Instead, you get variability in what people pull and how they apply it, longer cycles because validation gets pushed downstream, and more risk because the system can generate convincing output faster than your org can reliably govern.

What Real GTM Intelligence Actually Requires
If you want systems that do more than fetch content, you need more than wrappers and connectors. You need representation, which means the system has a model of what each asset actually is, why it exists, how it should be used, and when it is appropriate.
Representation goes beyond indexing text for retrieval. It encodes the attributes that determine whether something is safe and useful in a real GTM moment, including recency, audience, segment, region, approval status, source-of-truth ownership, and the relationships between assets. Once those properties are explicit, the system can reason across inputs instead of simply returning whatever happens to match a query.
This is the foundation of how we've built Mash.
We don't treat everything as flat text, and we don't treat every file in Google Drive or SharePoint as "just a document." A security questionnaire is fundamentally different from a compliance policy, and both are different from a draft case study that never launched, a pricing one-pager that was superseded last quarter, or a competitive battlecard meant only for internal use.
A customer quote is not just a sentence; it is tied to a feature area, a customer segment, a permission boundary, a timestamp, and an outcome that may or may not generalize to the deal in front of you. A deck is not just a file; it is a narrative built for a specific audience at a specific point in time, connected to product releases, messaging updates, and the proof points that were approved when it shipped. Support tickets, call recordings, QBR notes, slide snippets, and enablement docs each carry different signals and risks, so we represent them differently based on how they behave inside GTM workflows.
From there, Mash applies logic to evaluate relevance and risk before content is ever surfaced. It can recognize when a new product launch invalidates older slides, when a proof point only applies in a specific vertical, or when an asset is technically "available" but not approved for external use. Instead of optimizing for keyword match density, it computes reliability and applicability, which is what lets AI help reps act with confidence rather than simply search faster.
That's what enables AI to help reps act, not just search.

Why This Should Matter to Revenue Leaders
If you lead a revenue team, the challenges you're solving tend to be bigger than "finding information." You're trying to drive consistent messaging across every rep and every channel, shorten sales cycles without cutting corners, and build real knowledge momentum across divisions like Sales, Marketing, and PMM so performance and context do not live in the heads of a few people.
None of that is solved by raw access to data alone. What your team needs is judgment at scale, meaning a system that can help them apply the right content in the right moment, with the right constraints, without forcing them to second-guess every answer or chase alignment across six different tools.
AI systems that rely purely on MCP-style retrieval are not going to deliver that, because access is table stakes. Context is the hard part.
Consider the difference between pulling up a venue's seat map and asking, "What are the best seats for this game?" versus calling someone who's been to that stadium a dozen times and knows exactly how different sections feel in real life.
The seat map gives you access to everything: every section, every row, every price point, and plenty of opinions if you're willing to dig. But it doesn't know what "best" means for your situation. Are you bringing kids and want easy bathrooms and quick exits? Do you care more about being close to the action or having the full-field view? Are you cheering for the home team and want to be in that energy, or are you trying to avoid it? The information is all there, but you still have to translate it into a decision.
That's the difference between access and application. Between searching and reasoning. Between a wrapper and a real intelligence layer.
The Role MCPs Still Play, And Where They Stop
To be clear, MCPs are still valuable. They simplify integration, reduce plumbing work, and make internal systems more accessible to applications, bots, and agents. They should absolutely be part of the infrastructure layer.
But they are not built to model GTM workflows, resolve contradictions across content, or deliver judgment at the moment of decision. They can fetch "everything," but they can't reliably tell what's current, approved, segment-specific, or safe to use, and when that raw output gets fed into an LLM it can come back sounding confident while still being wrong or misapplied.
So yes, use MCPs for access, but don't confuse access with intelligence. If you're investing in AI for Sales, Success, or Enablement, it's worth asking:
Do you want systems that simply retrieve content, or systems that help your teams make better decisions and nail every customer interaction while reducing internal friction and repeated answers across the org?
Conclusion: From Knowledge Access to Knowledge Understanding
A lot of tools today position themselves as "AI knowledge" for GTM, promising broad integrations and quick answers through increasingly sophisticated MCP layers. And those layers are getting better—LLMs can now chain MCP calls, attempt multi-hop reasoning, and improvise their way through complex questions in real time. But "can attempt" is not the same as "reliably delivers."
When the underlying tools are generic CRUD connectors and the domain logic lives entirely in the LLM's on-the-fly reasoning, you're still betting on improvisation at the moment that matters most. The integrations get broader, but the intelligence stays shallow—because the system has no native understanding of what GTM work actually requires.
What these systems don't do is reason about content in a GTM-native way. They aren't applying narrative structure, permissions, audience targeting, or change over time, and they don't reflect how GTM teams really operate when messaging, collateral, and proof points evolve week to week.
At Mash, we take a different approach. We treat knowledge as a living system where every asset, conversation, and document is represented appropriately and connected through a GTM-aware model. That's what enables us to deliver more advanced, insightful recommendations that are not just fast, but safe, timely, and genuinely useful in practice.
For AI to truly support your revenue team, it has to do more than retrieve—it has to reason.
MCPs help make systems interoperable. They reduce technical friction. But they are not enough to support the real complexity of modern GTM work. They don't know what's current, what's risky, or what applies to a given deal, persona, or moment.
At Mash, we're building the layer that does. A system that understands context, models relationships, and helps your team act with confidence—not just faster, but smarter.
Because access gets you to the data. Understanding gets you to the answer.